



AI時代の幕が開く ChatGPTとは何か?
2023年7月14日2022年11月、米企業OpenAI(*1)より、「ChatGPT」が公開されました。人間が入力したテキストに対して、あたかも人間の意図を理解しているかのようにテキストを返答(生成)することから、リリース直後から話題を呼び、ユーザーは2カ月で1億人を突破しました。なぜChatGPTで自然な会話が可能となったのでしょうか。ここでは、野村證券フロンティア・リサーチ部による最新の調査レポートを基に、話題のAIアプリケーション、ChatGPTについて説明します。
*1 もともとは、2015年に現CEOのサム・アルトマン氏やイーロン・マスク氏らが設立したAIの研究開発を行う非営利法人。2019年にその子会社として営利企業OpenAI LPが設立されている
ChatGPT はなぜ会話ができる?
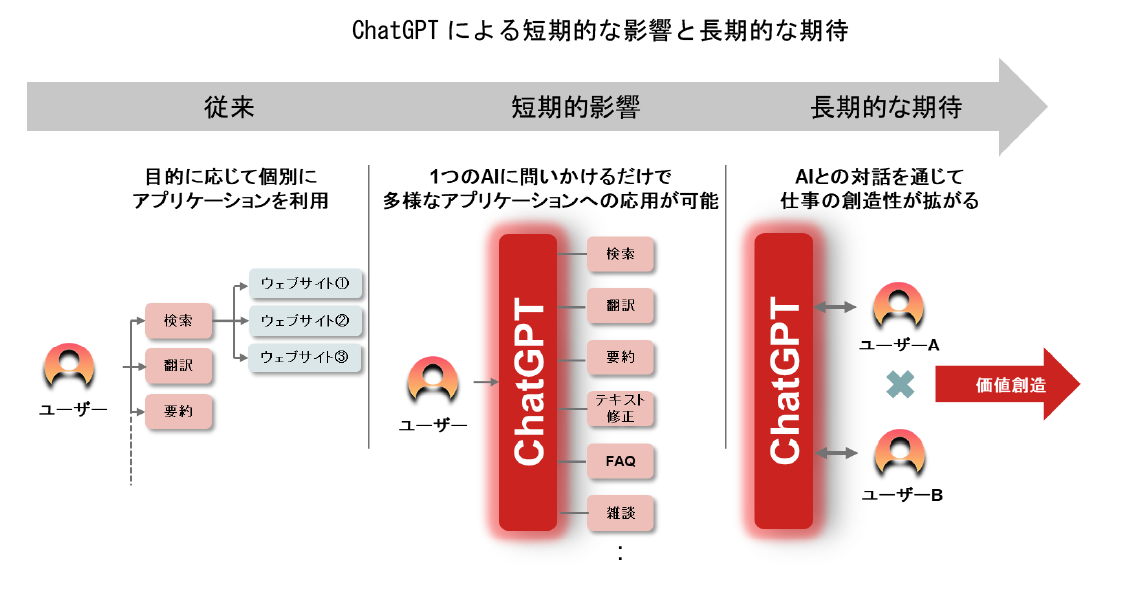
ChatGPTの画期的な点は、テキスト入力だけでさまざまなアプリケーションへの応用が可能となる、汎用性の高さにあります。例えば、入力テキストの語尾を「~について教えて」とすれば、AIが検索結果をまとめたようなテキストを生成してくれるので、検索エンジンの代わりになります。「~の文章を英語に翻訳して」とすれば、自動的に翻訳してくれますから、翻訳ソフトウエアとしても使えます。
さらに、ChatGPTが出力したテキストに不明な部分があれば、「今出力してくれた~とはどういう意味ですか」と追加で質問することもできます。「なぜ?」「なぜ?」と無制限に対話を深掘りすることで、ユーザーの理解も深まりやすくなります。
ChatGPTは、その汎用性の高さゆえに、短期間で多くの用途特化型ビジネスソフトウエアに多大な影響を与えると見られます。ChatGPTと提携することで既存のソフトウエアに、①会話型ユーザーインターフェイスの実装、②翻訳や要約といった機能を付加することができるなど、多様なタスクに応用が可能であり、すでに多くの企業や自治体、学校などで導入が進んでいます。
またChatGPTの本質的な価値は、テキストベースで保存されている世界中の英知を広く学習することで、言語や専門領域の壁にとらわれずに、あらゆる領域の発想を掛け合わせたアイデアの創発が可能になることにあると考えます。今後、AIとの対話を通じて知見の広さと深さを兼ね備えた人材が育ち、新しい価値が創造されることが期待されます。
では、なぜChatGPTは、「あたかも人間の意図を理解しているかのように」会話ができるのでしょうか。
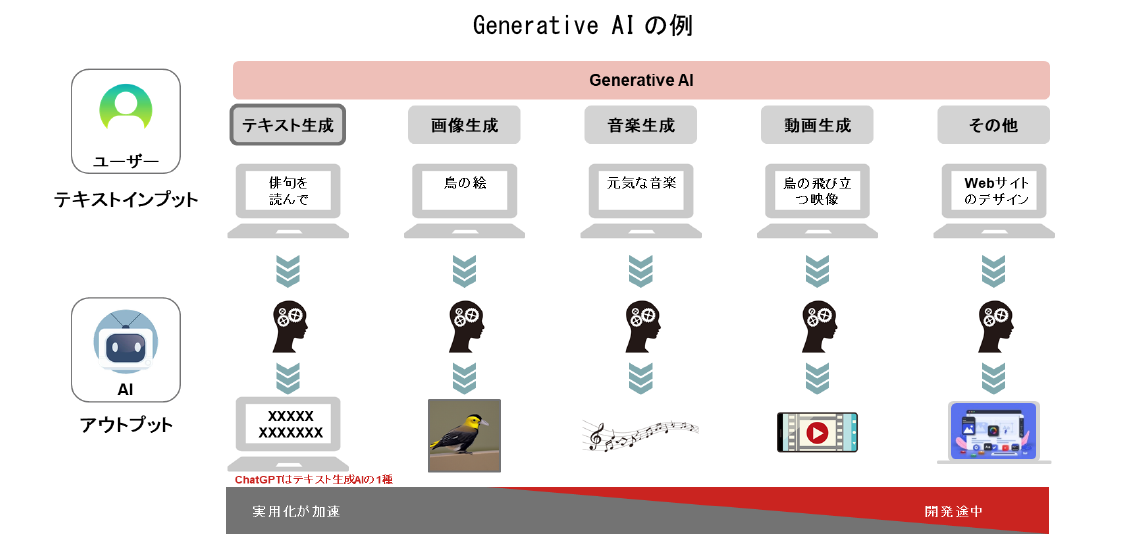
ChatGPTのように、自然言語(人間が話す言語)、画像、動画、音声などを学習し、新しい独自コンテンツを生成するAIのことを、ジェネレーティブAI(Generative AI)、または生成AIなどと呼びます。
AIとはArtificial Intelligenceの略で、人間の知的能力を模倣して実行できるように作られたシステム、いわゆる「人工知能」のことです。ジェネレーティブAIは、例えば「黄色い体で 黒い羽根で 短いくちばしの鳥の絵」とテキストを入力すると、AIがテキストのイメージと近い画像を出力してくれます。同様に「俳句を詠んでください」と入力すれば、五七五の俳句を出力する、といったことが可能です(下図参照)。
(野村證券作成)
ジェネレーティブAIとは、人間による言葉の入力(=与えられたデータ)から、文章や画像、音楽などの新しいデータを生成する機能を持った人工知能といえます。そのうちChatGPTは、人間が入力したテキストに対してテキストを出力する、テキスト生成型のAIアプリケーションということになります。
そして、テキスト生成型AIは、「大規模言語モデル」(Large Language Models:LLM)と呼ばれる、自然言語処理のために作られた人工知能のモデルをベースに作られています。自然な会話が可能となるカギは、この大規模言語モデルにあります。
≪ChatGPT理解のための補足≫
「大規模言語モデル」とは、インターネット上から集められた膨大なテキストデータを「深層学習」(ディープラーニング)によって構築した言語モデル(次に来る言葉の出現確率を表したモデル)のこと。ここでいう「学習」とは、AIが与えられた数多くのテキストから、一定のルールやパターンを見つけ出す「機械学習」のことを指します。そして深層学習とは、この機械学習を進めるための技術のひとつで、ルールやパターンの発見が自動的に進められるという特徴があります。
大規模言語モデルと深層学習は、ChatGPTやジェネレーティブAIを理解するうえで重要な言葉です。以下に掲げた動画がわかりやすくその意味するところを説明しています。ぜひご覧いただき、用語の意味を理解したうえで次の文章にお進みください。
大規模言語モデルとは
深層学習(ディープラーニング)とは
※野村総合研究所(NRI)データサイエンスラボYouTubeチャンネルの動画を、許可を得て掲載しています
大規模言語モデル「Transformer」
大規模言語モデルが登場する以前、テキストをニューラルネットワーク(人間の脳の神経細胞の働きに着想を得て作成された数学モデル)で処理する場合、時系列データに対応したRNN(Recurrent Neural Network)が使用されていました。RNNは文頭から順番に単語を1つずつ処理していくことから、テキストを要約したり、翻訳したり、人間と雑談したり、といった長文を読み取る必要があるタスクは苦手でした。
しかし2017年12月、Google(米Alphabet)の研究部門であるGoogle BrainとGoogle Researchが、「Attention Is All You Need」(アテンションだけでいい)という論文を発表します。この論文で述べられていたのが、大規模言語モデル「Transformer」です。
Transformerは、その名前が表すように機械翻訳のための大規模言語モデルでしたが、自然言語処理の能力そのものを非常に高めた画期的なモデルで、 AIが単語の意味や関係性を捉える精度が飛躍的に高まりました。高度な自然言語処理能力が備わったTransformerの発表以降、これをベースとする大規模言語モデルが、次々と発表されることになります。そして2018年6月、Open AIがChatGPTの原点となる、GPT(Generative Pre-trained Transformer)を発表しました。モデルの原型となったのは、やはりTransformerです(※2)。
※2 2018年10月、Googleが「Transformer」を基にした大規模言語モデル、「BERT」(Bidirectional Encoder Representations from Transformers)を発表。その自然言語処理能力の高さにおいて大きな注目を浴びるが、ここでは割愛する
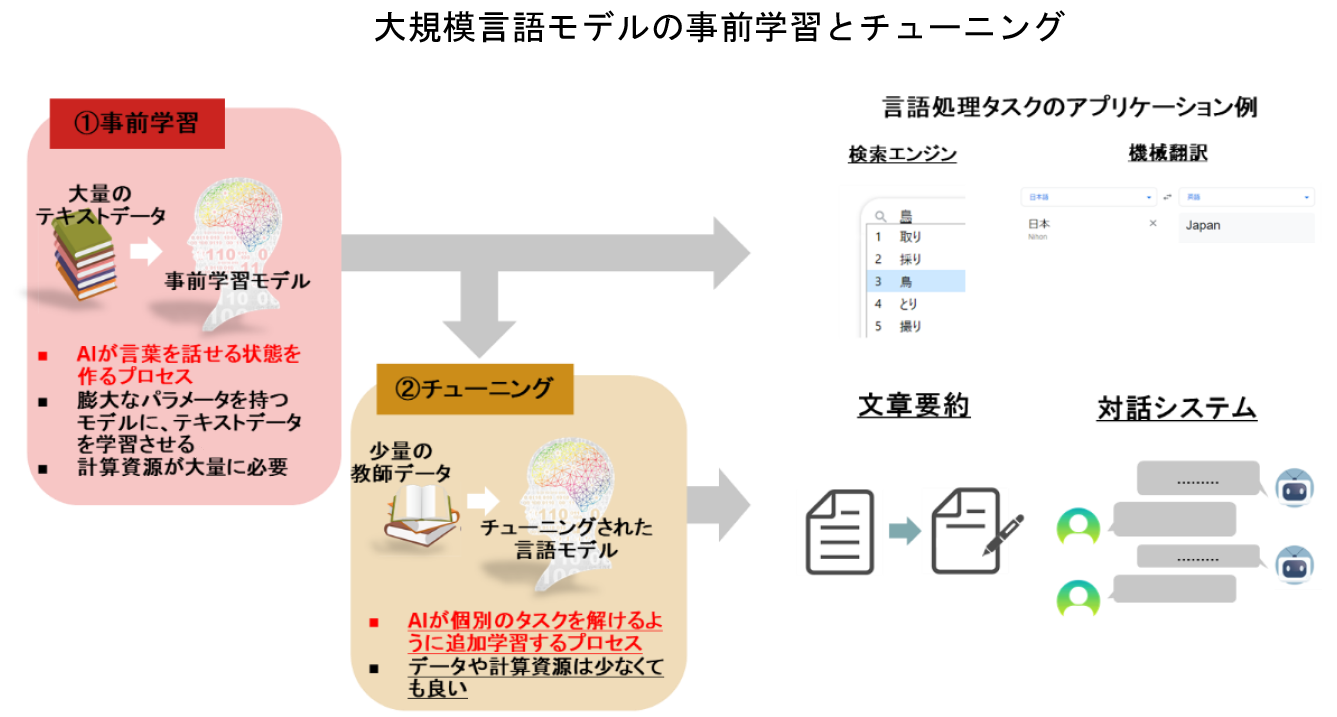
GPTの構造は、大規模な言語データから事前に学習する「事前学習プロセス」と、特定のタスクを解けるようにするための「ファインチューニング」(目的に合った学習データを追加し、全体の調整を行うこと。単に「チューニング」とも呼ばれる)に分かれています。
大規模言語モデルの事前学習に必要なデータは膨大で、学習には時間がかかります。そのため、実際に大規模言語モデルを利用する際には、大手企業や研究機関がインターネット上に公開している事前学習済みのモデルをダウンロードしたり、利用のための連携をしたりすることで、特定のタスクに合わせてチューニングすることが一般的です。
また、直近の大規模言語モデルは非常に精度が高く、事前学習したモデルをそのまま利用しても、高精度のアウトプットを得られるようになっています。
(野村證券作成)
大規模言語モデルの性能は、①モデルのパラメータ数、②学習するデータセットのサイズ、③モデルの訓練に使用するコンピュータの計算能力の、3点に依存します。これをScaling Law(大規模言語モデルをスケールさせるための規則)といいます。大規模言語モデルの開発に際しては、これらのバランスを適切に調整することで、最適なモデル性能を達成することができます。
なかでもパラメータ数は、多ければ多いほど入力テキストを表現できるベクトルの幅が増え、結果的に多様な表現のテキストが出力可能となります。2019年2月、OpenAIはGPTを改良したGPT-2を発表。GPTはモデルのパラメータ数が1.17億だったのに対して、GPT-2は15.8億と10倍超になりました。GPT-2は、モデルを大規模化したことで、チューニングを行わずに自然な文章を生成することを可能にしたのです。
さらにOpenAIは、翌年5月にGPT-3を発表し、パラメータ数はさらに増えて1,750億に。GPT-4(2023年3月発表)ではパラメータ数は非公表となりましたが、GPT-3より大幅に増加していると推測されます。
なお、大規模言語モデルは、学習が完了して以降に生み出されたテキストについては学習していないというところに注意が必要です。例えば、2021年9月に学習が完了した大規模言語モデルは、2023年の流行語や新たな有名人、出来事を加味して返答することができません。最新のコンテキストを加味したアウトプットを得たい場合は、最新データを適宜追加学習させ、モデルをアップデートする必要があります。
≪ChatGPT理解のための補足≫
高い自然言語処理能力を持つChatGPTですが、ChatGPT自体は、入力テキストに対して人間が自然と思える回答を確率論的に生成しているにすぎません。そのため、ChatGPTは意図せず虚偽の回答をすることがあるうえに、未学習の最新情報の取り込みは不得意、といった課題があります。
ジェネレーティブAIの主なプレーヤー
ジェネレーティブAIのプレーヤーを大きく分けると、「アルゴリズムの基礎開発を行うプレーヤー」と、「開発されたアルゴリズムを活用してアプリケーションを提供するプレーヤー」に分かれます。アルゴリズム開発には、膨大なテキストや画像のデータを集め、GPU(*3)で処理するスタックを組む必要があることから多額の投資を要し、プレーヤーは大手企業が多くなります。
*3 Graphics Processing Unitの略。膨大な量のデータを高速で処理できるという特徴がある半導体チップで、生成AIの活用に適しているといわれる
GoogleとOpenAIは、画像生成とテキスト生成の両方のアルゴリズムを開発しています。OpenAIは2019年の段階で、米Microsoftから10億ドルの出資を受けており、MicrosoftはGPTシリーズを独占利用するライセンスを取得しています。ジェネレーティブAIのアルゴリズム開発では、OpenAIを擁するMicrosoftとGoogleという大手米国テクノロジー企業による熾烈な競争が展開されているといえます。
日本語版の大規模言語モデルを実装するプレーヤー、あるいはアルゴリズムには、Microsoft出身者が立ち上げたrinna(未上場)、メッセンジャーアプリを通じて膨大な日本語データを所有するLINE (Zホールディングス[4689])の「HyperCLOVA」、AIの研究で著名な東京大学・松尾研究室のメンバーが立ち上げた自然言語処理ベンチャー企業のELYZA(未上場)の「ELYZA Brain」などがあります。
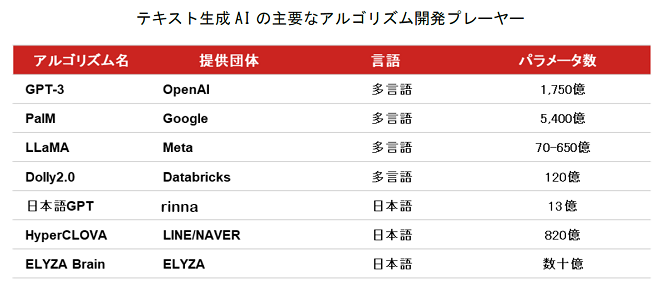
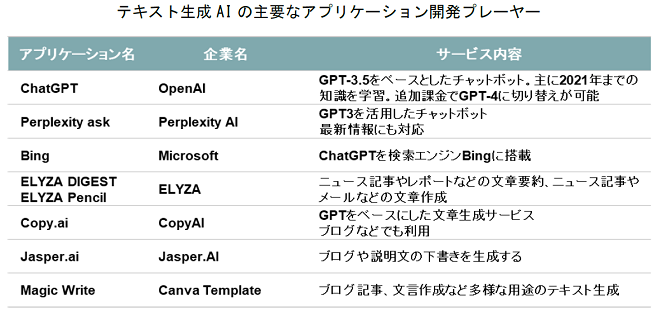
アプリケーションは、ChatGPTを中心に、情報収集や文章要約を目的としたものが多数あります。「Copy.ai」はGPTをベースに、キャッチコピーやブログを自動生成するサービスです。いずれのアプリケーションも、言語モデル作成後に記述されたテキストを学習できないので、近年発生したイベントについては知識が限られています。最新情報の取り込みや、ファクトチェックの仕組みを取り入れることが今後の課題となるでしょう。

ここまで、ChatGPTを理解するために必要と思われる情報をまとめました。しかし、ジェネレーティブAIをめぐる進化は非常に著しく、産業界へのインパクトも非常に大きなものになっていくことが予想されます。IRマガジンでは、今後もAIにおける技術革新が及ぼす影響を、わかりやすくお伝えしていく予定です。
制作協力/野村證券フロンティア・リサーチ部 中野友道
※当記事は野村證券フロンティア・リサーチ部による「Industry Research Report」のNO.282「Generative AI 2 ~大規模言語モデルとChatGPTの衝撃~」をベースにIRマガジン編集部が制作しました